
In previous articles on methods for improving product quality with LLMs, we discussed both basic approaches and the advanced method of using RAG. This time, we’ll explore how fine-tuning can be applied to LLM-based products.
Typical LLM-based product scheme
Let’s recall the simplified scheme of a typical product or feature based on LLM:
- There is a user problem that needs to be solved.
- A prompt is formed based on the understanding of the problem.
- The prompt is passed to the LLM.
- The LLM generates a response, which is then processed by the product and returned to the user.
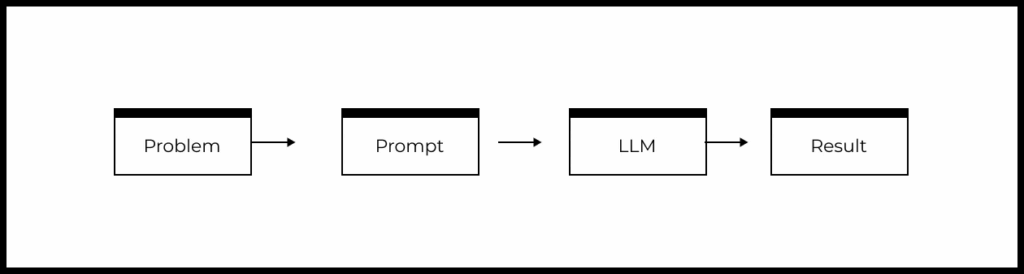
From the above diagram, we can identify the following levers that can affect the quality fo the LLM-powered feature or product:
- Formulation of the problem to be solved with the help of LLM
- Modification of the prompt
- Changing the model and/or its parameters
With the help of fine-tuning, we can influence the LLM’s performance on specific tasks.
First, we will understand LLM fine-tuning and typical situations where it can be beneficial. After that, we will review examples of fine-tuning applications.
Fundamentals of LLM fine-tuning
Fine-tuning is a process where a general model, already trained on a large volume of data (e.g., GPT-5), is further trained on a new dataset specializing for a specific task.
This process allows the model to better handle these tasks or understand the nuances of new data.
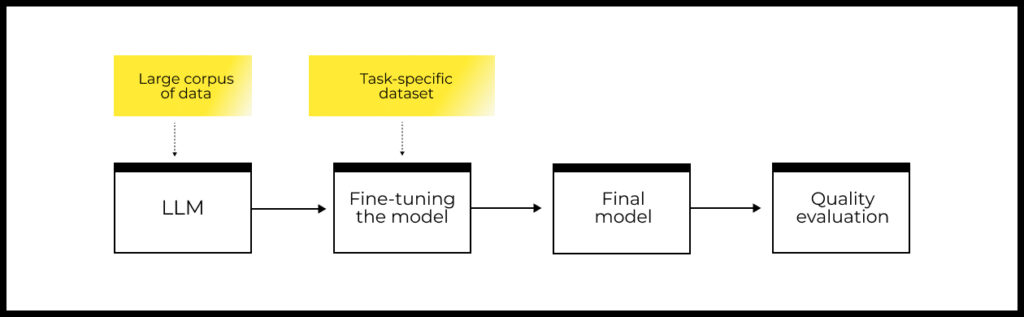
To implement fine-tuning, you need:
- A dataset containing examples specific to your task (a few hundred or thousand examples in the dataset are sufficient).
- A model that can be fine-tuned: this could be an open model (LLaMa, Mistral, etc.) or a cloud-based fine-tuning service for a commercial model (e.g., OpenAI API for fine-tuning GPT models).
- A procedure for evaluating the quality of the solution.
Fine-tuning LLMs is typically performed by an AI engineer.
When to use fine-tuning
Fine-tuning can be beneficial if you need to:
- Work with specialized data
- Perform document classification
- Obtain responses in a specific structure or style
- Optimize the speed and cost of using LLMs
Advantages of Fine-tuning:
Fine-tuning is the best choice if you need the highest possible quality in processing specialized data or want your responses to be in a complex structure/style. Other methods (RAG, prompt optimization, etc.) cannot surpass fine-tuning in quality.
Disadvantages of Fine-tuning:
The most significant limitation of LLM fine-tuning is the need for a dataset specific to the task at hand. It is important to note that the dataset must have several hundred or thousands of examples.
Even with sufficient data, LLM fine-tuning can be complex and costly.
The complexity LLM fine-tuning is due to:
- The need for qualified engineers in the team who are skilled in working with LLMs
- A large number of different fine-tuning options (various models, different parameters, diverse datasets, changing the problem statement)
- The absence of guaranteed success
The cost of the solution consists of the cost of:
- Data preparation for fine-tuning
- The fine-tuning of the LLM itself
- Preparing the infrastructure within the company.
It is always useful to estimate approximate timelines and costs before starting work and then decide on their feasibility for the business.
Another disadvantage is that fine-tuning the LLM can sometimes result in the model losing some of the capabilities and knowledge it had acquired during pre-training.
Over time, data can change, so it’s worth considering monitoring the model’s performance, collecting updated data, and repeating the fine-tuning process when needed. Regular fine-tuning should also be factored in when evaluating the cost of the approach.
When not to perform fine-tuning
Keep in mind that you shouldn’t engage in LLM fine-tuning if you’re creating a new product and haven’t yet achieved product-market fit:
- In the early stages of working on a product, in the vast majority of cases, it makes sense to use frontier LLMs (GPT-5, Claude 4) without fine-tuning them.
- Before considering fine-tuning, it is necessary to establish a process for evaluating the quality of LLM solutions and have a baseline for deciding on the feasibility of experiments with fine-tuning.
Fine-tuning small language models
There is currently a trend towards using small language models (SLMs), which:
- Are the result of fine-tuning standard small open-source models and are further trained on the outputs of large language models for specific tasks.
- Significantly reduce the cost of using language models.
- Have quality that is comparable to the most powerful LLMs in certain tasks.
- Reduce the risks associated with sending data to third-party cloud services, as they operate within the company’s perimeter.
Case study of implementing an AI character
Imagine you want to create an AI character that speaks like Steve Jobs, adhering to his style of responses in both content and form.
You will need a dataset consisting of as many speeches by Steve Jobs as possible. In this case:
- The dataset is a collection of Steve Jobs’ speeches (simply a set of text documents).
- Language models are trained through self-supervised learning. This means there is no need to manually label target variables, and instances are automatically formed from the text itself.
This dataset will reflect the specifics of Jobs’ speech, and it can be used to fine-tune a large language model, such as GPT-5.
Let’s consider an example from Jobs’ speech to Stanford graduates in 2005:
“I am honored to be with you today at your commencement from one of the finest universities in the world. I never graduated from college. Truth be told, this is the closest I’ve ever gotten to a college graduation. Today I want to tell you three stories from my life. That’s it. No big deal. Just three stories.”
Recall that a language model solves the task of predicting the next word based on the existing text.
Our text fragment can be transformed into a set of instances based on this principle. For simplicity, let’s choose a window of 10 words for text segmentation, here’s what we get:
- I am honored to be with you today at your
- am honored to be with you today at your commencement
- honored to be with you today at your commencement from
- to be with you today at your commencement from one
- and so on
The essence of fine-tuning lies in the need for a language model to predict the tenth word (this is the target variable) based on the previous nine words (these nine words are the input).
This is a simplification of the real process but maintains the key elements.
AI assistant case for legislation
Imagine you want to create an AI assistant for the legislative issues of a specific country or state. Legislative norms differ significantly between countries. Therefore, it is preferable to prepare a dataset with regulatory documents for each country and fine-tune separate models for each dataset.
Unlike the previous example, the task here is to generate correct answers to legal questions, rather than creating new legal documents. For this scenario, we require supervised fine-tuning:
- We need an annotated dataset consisting of texts in the format “question — correct answer.” More generally, this is a “prompt — response” format.
- The examples from the annotated dataset will then be used to generate instances and target variables for further training.
Case study: analyzing support service requests
If you want to determine the category of user requests to a support service, fine-tuning can be useful.
In this case, you need to use supervised fine-tuning (as in the previous example):
- We will need a labeled dataset consisting of texts in the format “user request — request category”.
- The target variable will be the request category. Categories are usually encoded with numbers so that the model’s task is reduced to predicting exactly one token.
- The instance will be the text of the customer request.
Evaluating the quality of fine-tuning
Evaluating fine-tuned LLMs is similar to supervised machine learning models. In essence:
- It is necessary to split the dataset into train and test datasets.
- The train dataset is used to fine-tune the model.
- The test dataset is used to evaluate the quality of the fine-tuned model.
To evaluate the improvement in quality after fine-tuning, we can compare the metrics before and after fine-tuning (i.e., when simply using the original large language model).
Fine-tuning is quite a complex process with numerous parameters, so it is always critically important to conduct quality assessments to understand whether the fine-tuning was done correctly and is beneficial.
Fine-tuning LLM: summary
Fine-tuning LLMs is the process of further training a large language model, meaning that a general large language model is additionally trained on a new specialized dataset.
Fine-tuning can be beneficial if you need to:
- Working with specialized data.
- Document classification.
- Adhere to a strict structure/style of responses.
- Optimize the speed and cost of using LLMs.
Advantages of fine-tuning:
If you need the highest possible quality in processing specialized data or producing responses that adhere to a complex structure/style, fine-tuning is the best choice. Other methods (RAG, prompt optimization, etc.) cannot surpass fine-tuning in quality.
Disadvantages of fine-tuning:
Fine-tuning an LLM requires a dataset specific to the task at hand (a few hundred or thousand examples in the dataset are sufficient).
Fine-tuning is a rather complex process with numerous parameters, so it is always critically important to conduct quality evaluation to understand whether the fine-tuning was done correctly and is beneficial.
Relevant articles:
- Basic guide to improving product quality with LLM
- Advanced methods for improving product quality with LLM: RAG
- Advanced methods for improving product quality with LLM: fine-tuning [you are here]
To enhance your skills in working on AI products, you can benefit from:
- AI/ML Simulator for Product Managers
- Generative AI for Product Managers – Mini Simulator
- AI Prototyping Simulator
Illustration by Anna Golde for GoPractice