
Large Language Models (LLMs) can effectively automate tasks in product development, saving both business costs and employees’ time. However, implementing these tools doesn’t guarantee immediate quality results, so knowing how to enhance their performance is important.
In this article, we will explore basic approaches for improving features and entire products that use large language models.
Levers of influence on product quality with LLM
A simplified scheme of a typical LLM-based product or feature can be represented as follows:
- There is a user problem that needs to be solved
- Based on the understanding of the problem, a prompt is generated
- The prompt is sent to the specified LLM
- The LLM generates a response, which is processed in a certain way within the product and returned to the user.
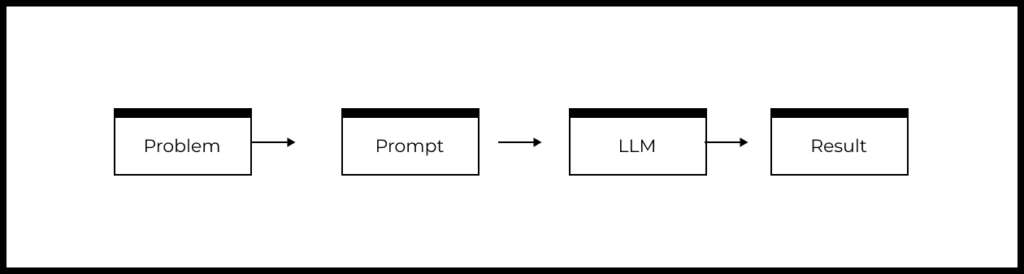
Based on the above diagram, the quality of LLM-based features or products depends on the following factors:
- What problem is being solved with the help of LLM,
- How the prompt is formulated.
- What model is used and its configuration.
Based on this, we can use the following basic methods to affect the quality of our product or feature:
- Improving the prompt
- Experimenting with different models and configurations
- Reformulating the problem
If the basic methods did not yield the desired quality, you use advanced methods:
- Retrieval-Augmented Generation (RAG, generation based on search results)
- LLM fine-tuning
- Few-Shot Learning
- External data sources and tools
- Prompt pipelines and LLM ensembles
- Use identifiers in prompts
- Re-evaluating LLM responses
In this article, we will discuss the basic methods for improving the quality of LLM responses. We will discuss more advanced methods in future articles.
Prompt improvement
Brief description
If you are not satisfied with the quality of the model’s responses (which implies that you can measure the quality of the model’s responses and understand the target variable for your product) it is useful to try applying the following modifications to your prompt:
Use clear and detailed instructions
- Specify the model’s role. For example, you can instruct it to be a product manager or an analyst conducting research and analyzing user feedback.
- Use delimiters for semantic blocks, such as “”, ===, < >, <tag> </tag>. There are no formal recommendations on which delimiters to use. Just make sure different semantic blocks are clearly separated.
- Specify the response format: JSON, HTML, table, or other.
- Instruct the model to verify whether all necessary conditions are met.
Give the model ‘time to think.’
- List the instructions for completing the task as a clear sequence of steps. Example: Step 1: do X, Step 2: do Y, …, Step N: do Q.
- Add the instruction ‘Solve the problem step by step’ to the prompt.
- Ask the model to explain its answers.
When to apply prompt improvement
Use prompt improvement when the LLM generally shows acceptable results (it handles the problem in some situations) but the proportion of correct answers is below the target level.
The usefulness of recommendations should be verified separately for each specific problem.
Example of prompt improvement
Suppose you want to analyze user reviews about a product. For this, you want to identify the topics in the reviews and their sentiment – positive/neutral/negative.
Let’s look at the first version of the prompt (Prompt V1), where {{Review text}} is the text of the user review.
Prompt V1:
You are a product manager who has to research user experience of your app.
Your task is to analyze a review and extract main topics (maximum 3 topics).
For each topic extract related sentiment – positive/negative/neutral.
Here is a text of a review.
===
{{Review text}}
===
Output a RAW json with format
{
“topic_name”: “sentiment”, …
}
On the sample of Twitter/X app reviews from the App Store, this prompt performed quite poorly:
| Prompt Version | Share of Relevant Topics | Share of Excessive Topics | Share of Topics with Correct Sentiments |
|---|---|---|---|
| Prompt V1 GPT-3.5 | 0.64 | 0.13 | 0.88 |
Now let’s use recommendations to improve the prompt and try prompt V2 (where {{Review text}} is the text of the user review):
You are a product manager who has to research user experience of your app.
You must analyze the following review and extract the main topics about the app (maximum 3 topics, minimum – 0 topics).
Each topic has to describe an exact feature or issue of the app. It should be actionable for a product manager.
If there are no exact topics about the app in the review, then return “No topics”.
Step 1: Extract the first main topic about the app.
Step 2: Extract the second main topic about the app. Compare this topic with the first one. If they are similar, then only use the first topic.
Step 3: Extract the third main topic about the app. Compare this topic with the first and the second ones. If they are similar, then use only previous topics.
Step 4: Check if extracted topics are really about exact features or issues of the app.
If not, then return “No topics”.
Step 5: If you extracted topics, then for each extracted topic, define the sentiment in the review
– positive/negative/neutral.
Sentiment has to be related to user’s perception in the present, words such “now” could describe current sentiment.
Here is a text of a review.
===
{{Review text}}
===
Solve this task step by step.
Output a RAW json array with format
[{
“explanation”: “explain your decision here”,
“topic_name”: “extracted_name”,
“sentiment”: “extracted_sentiment”
}, …]
What we changed:
- More precise instructions regarding the number of topics, as well as separate logic for responses when there are no relevant topics:
- “maximum 3 topics, minimum – 0 topics”
- “If there are no exact topics about the app in the review, then return ‘No topics’.”
- The sequence of specific steps for extracting topics in a review:
“Step 1: Extract the first main topic about the app.”
Step 2: Extract the second main topic about the app. Compare this topic with the first one. If they are similar, then use only the first topic.
Step 3: Extract the third main topic about the app.
Compare this topic with the first and the second ones. If they are similar, then use only previous topics.
Step 4: Check if extracted topics are really about exact features or issues of the app? If not, then return ‘No topics’.
Step 5: If you extracted topics, then for each extracted topic define related sentiment – positive/negative/neutral.
Improvements in key metrics – relevance and redundancy (detailed results):
| Prompt Version | Share of Relevant Topics | Share of Excessive Topics | Share of Topics with Correct Sentiments |
|---|---|---|---|
| Prompt V1 GPT-3.5 | 0.64 | 0.13 | 0.88 |
| Prompt V2 GPT-3.5 | 0.72 | 0.13 | 0.85 |
We thoroughly examine the case of automatic user review analysis using GPT in our six-hour course Generative AI for Product Managers.
Experiments with models and configurations
Brief description
To improve the quality of the responses, you can try changing the LLM or modifying its configurations.
New models are constantly appearing on the market, old ones are being updated, and the conditions for working with them are changing (cost, API, regulations).
Examples of popular models: GPT-3.5, GPT-4, GPT-4o, Gemini, LlaMA, Falcon, Mistral, Claude. You can check Hugging Faces LLM Leaderboard best models and LMSYS Chatbot Arena Leaderboard for a comparison of different open models.
The quality of different models (ChatGPT, Claude, Gemini, Llama, etc.) might vary across different types of problems.
In general, more advanced LLMs provide higher-quality responses. For instance, GPT-4 will almost always have better-quality responses than GPT-3.5. Navigating among the versions of GPT models can be facilitated by the OpenAI documentation.
However, using a more advanced model is not always justified, as it is more expensive and for some problems, simpler models can yield similar results.
For certain problems, it is useful to experiment with model settings such as temperature and the number of output tokens.
Temperature controls the variability of responses: the higher the temperature, the more varied the LLM’s response will be. Higher temperatures are more suitable for creative problems, such as coming up with a name for a new game or writing an advertising slogan. When working with GPT-4, for some problems, the results are consistently better with a temperature of 1 rather than 0.
For GPT models, specifying the number of output tokens can significantly influence the response you receive. Even short answers can vary greatly depending on whether the number of output tokens was specified or not.
When to experiment with models and their configurations
If basic prompt improvement recommendations didn’t help, try using a more advanced model. For complex problems, we recommend starting with the most advanced models right away.
It is crucial to closely monitor changes in the models you use and to regularly experiment with new models and use them if they add business value.
When experimenting with new models, keep the following details in mind:
- When changing a model, always evaluate its quality.
- New models may require reselecting prompts and reevaluating quality on a sample set of examples.
New models can significantly increase or reduce the costs of your application. Therefore, it is necessary to carefully assess whether the expenses for the new model are justified from the perspective of project economics.
Example of using more advanced models
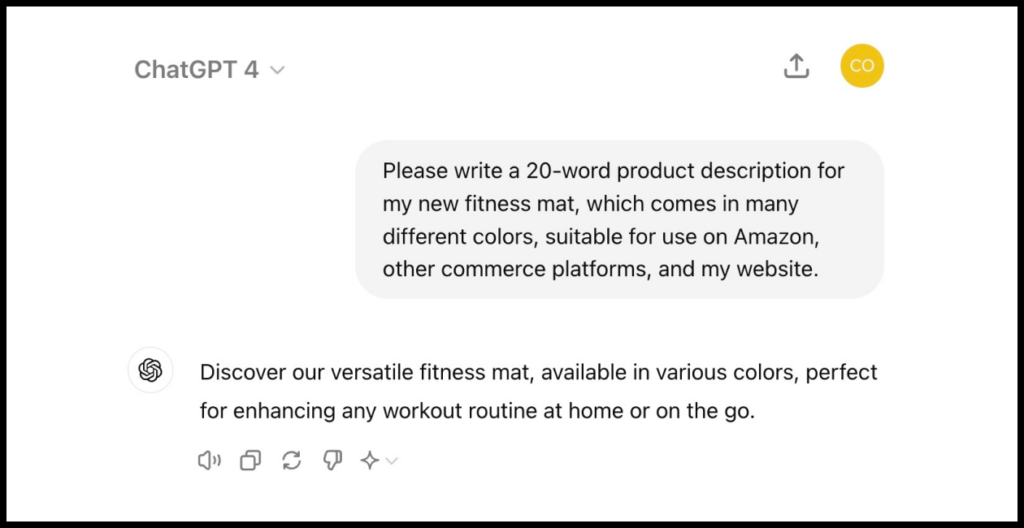
Imagine you need to create product descriptions for your marketplace, as sellers often provide poor descriptions or none at all.
Let’s compare the results of GPT-4 and Claude-3.5 for the following prompt:
Please write me a 20-word product description for my new fitness mat, which comes in lots of different colors. Make it suitable for use on Amazon and other ecommerce platforms, as well as on my website.
GPT-4 Response
Claude-3.5 Response
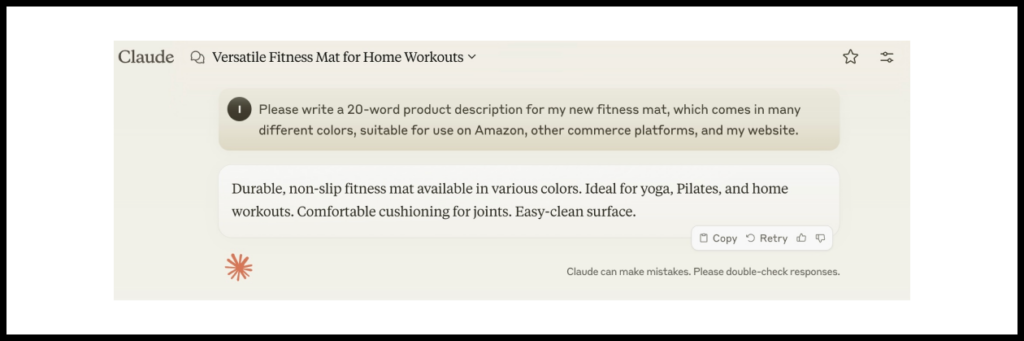
For this example, Claude-3.5 provided a more interesting description, which is better suited for product promotion.
Reformulating the problem
Brief description
Sometimes, it is worth rephrasing, decomposing, or even narrowing down the original problem to improve the quality of the final solution and user experience.
When to reformulate the problem
This approach is particularly relevant in the following situations:
You are trying to solve several problems in one prompt.
↓
Try solving individual problems with more specialized prompts.
You are tackling a summarization problem and the quality is poor.
↓
Try rephrasing it in terms of extracting specific fields and the next step – constructing a template response based on the extracted information.
You are trying to determine the topic of a user message in a chat and are faced with a large volume of messages where the topic is unclear.
↓
Try turning the problem into a dialogue with the user to clarify information.
Example of reformulating the problem
Let’s consider an example of analyzing client invoices in a bank. If you try to summarize information about all the fields of an invoice with a single prompt, you will likely get low-quality results.
For this problem, a combination of two approaches will work well:
Reformulating the problem
Instead of summarization, formulate the problem as field extraction. Then use a template to create the final response based on the extracted data points. Important invoice fields include the names of the seller and buyer, the invoice amount, payment date, invoice issuance date, and the description of the goods/services in the invoice.
Decomposition
Optimizing a separate prompt for extracting each field from an invoice can be beneficial.
Summary
We have reviewed the basic methods for improving the quality of LLM-based products and features:
- Prompt improvement
- Experiments with models and configurations
- Reformulating the problem
In practice, it is impossible to predict in advance which solution will be most effective for a specific problem. In each case, it is worth conducting experiments and evaluating the quality on several examples.
If basic approaches do not help achieve the necessary quality, then it is worth moving on to experiments with advanced approaches, such as:
- Retrieval-Augmented Generation (RAG, generation based on search results)
- LLM fine-tuning
- Few-Shot Learning
- External data sources and tools
- Prompt pipelines and LLM ensembles
- Use identifiers in prompts
- Re-evaluating LLM responses
We will explore these advanced methods in future publications.
===
To enhance your skills in working on AI products, the following courses will help you:
Illustration by Anna Golde for GoPractice