
In a recent article, we discussed basic recommendations for improving product quality with LLM.
In this editon, we will explore one of the advanced approaches — Retrieval-Augmented Generation (RAG) or generation based on search results.
The structure of a typical LLM-based product
Let’s review the simplified structure of a typical LLM-based product or feature:
- There is a user problem that needs to be solved.
- A prompt is designed based on the problem.
- The prompt is sent to the LLM.
- The LLM generates a response, which is processed by the product and returned to the user.
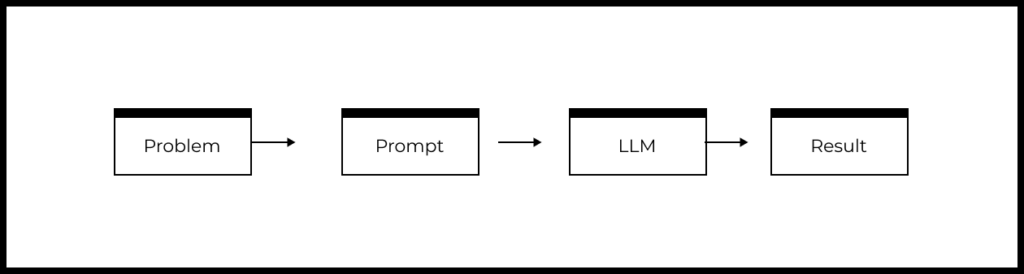
From the block diagram above, we can identify the following levers of influence on the quality of the feature or product based on the LLM:
- Problem
- Prompt
- Model and model configuration
With the help of RAG, we primarily influence the prompt by adding important information that can help improve the response.
First, we will discuss the basics of RAG and situations where it can be useful. After that, we will review real-world RAG applications.
How RAG works
The idea of RAG is that we enrich the prompt with knowledge that was absent from the training dataset of the large language model (LLM).
There are different variants of RAG, but the main steps of the approach are the same:
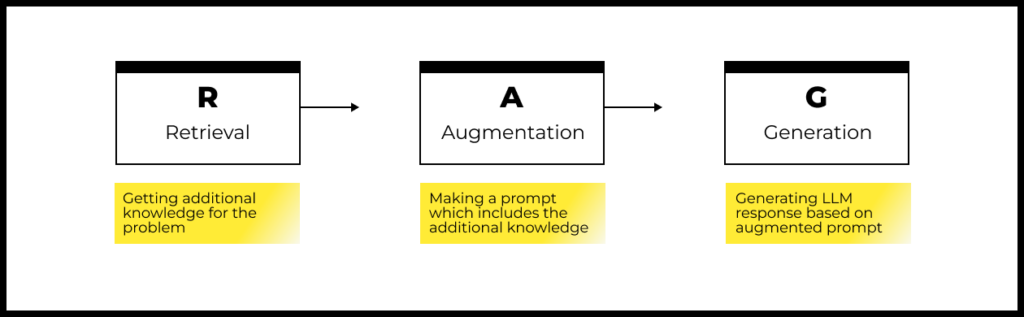
Step 1: Retrieval
Information is retrieved from data sources based on the user’s query. These data sources can include internal company databases, document repositories, external resources (search engines, specialized services, APIs).
Information retrieval is carried out either based on the original user query or a transformed version of it (for example, the user query can be converted into an SQL query, a set of search queries, embeddings).
The data obtained in this step will help enrich the LLM with additional information when responding to the user’s request.
Step 2: Augmentation
At this step, a prompt is composed from the original user query and the additional knowledge obtained in the retrieval phase.
The retrieved information can be modified to make the enriched prompt as accurate as possible, for example, through filtering, reranking, summarization, etc. These results should always be converted into text for use in the prompt.
The result of this step is the augmented prompt.
Step 3: Generation
At this stage, the augmented prompt is sent to a large language model (LLM). The model’s response can be significantly influenced by adjusting parameters such as temperature and the number of output tokens.
The model’s response can be modified, for example, by adding citations or references to the sources of the additional knowledge used in the enriched prompt. Additional verification of the model’s response can also be implemented.
Based on the result of this step, a response is then generated for the user.
When to use RAG
RAG can be helpful if you need to:
- Use information that was not present in the training dataset of the LLM.
- Increase reliability of responses and reduce hallucinations in the LLM.
- Provide links to the sources of information on which the response was based.
Advantages of RAG:
- It is relatively simple to implement:for some problems, it can be implemented in just five lines of code.
- It is faster and less costly than fine-tuning (retraining a large language model).
- It allows for the rapid replacement of sources of information for prompt enrichment.
Disadvantages of RAG:
- To use RAG in production, you need to maintain specialized infrastructure, which can be quite complex (the complexity depends on the specific problem and data sources for RAG).
- Evaluating the quality of RAG is labor intensive. The final result depends on multiple components, each of which needs to be evaluated separately (creating multiple test datasets, metrics, and annotations). For example, if it is necessary to add quotes from the data source, the quality of the quoting needs to be measured separately.
Case study: FAQ search
One common use of RAG is to turn a set of FAQ documents into an LLM chatbot that can answer users’ questions through a conversational interface.
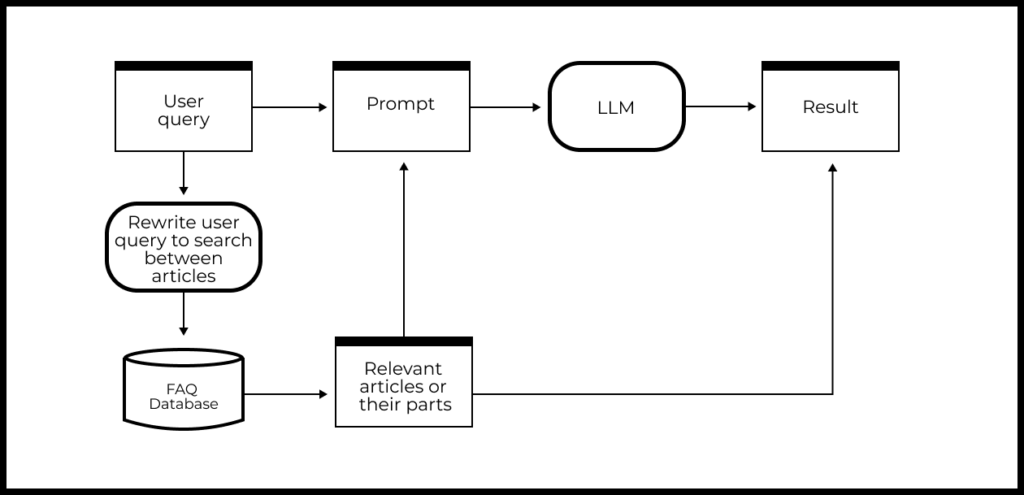
The implementation of such a FAQ-based chatbot might look like this:
- The user submits a question
- We perform a search among FAQ articles to get the most relevant one for the user’s query (if there are several relevant articles, we create a set or a ranked list).
- We compose a prompt based on the user’s query and the information found in the document(s).
- We send the enriched prompt with additional information to the LLM and receive the model’s response.
- We add links to source articles to the model’s response to obtain the final answer for the user.
Case study: A personal assistant for online shopping
Imagine you are responsible for a grocery delivery service and want to implement a new feature—a personal assistant. This assistant can help users adjust their shopping carts, for example, to make their diet more economical or more diverse.
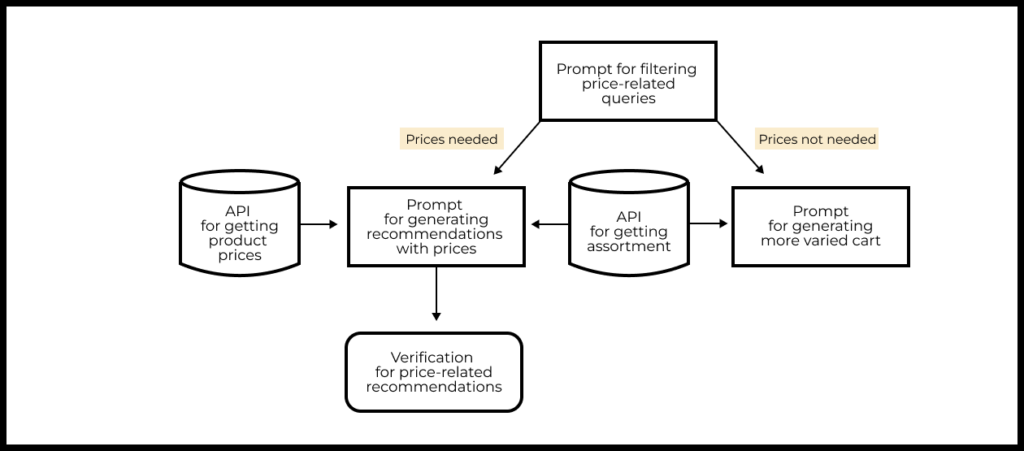
Implementing such an assistant is possible using LLM and RAG:
- We call API services that provide information about product assortments and prices.
- We compose a prompt to determine whether the request is price-related or not. If it is:
- We create a prompt for recommending less expensive products, enriched with product price information obtained through RAG.
- We recheck the model’s responses to ensure that all recommended products are indeed cheaper (this is advisable since LLMs do not handle mathematical operations very well).
- If the request is aimed at creating a more diverse basket, then:
- We form a prompt for recommending a more diverse range of products.
The online shopping assistant case study (GPT + RAG) is examined in detail in AI/ML Simulator for Product Managers.
Summarizing news
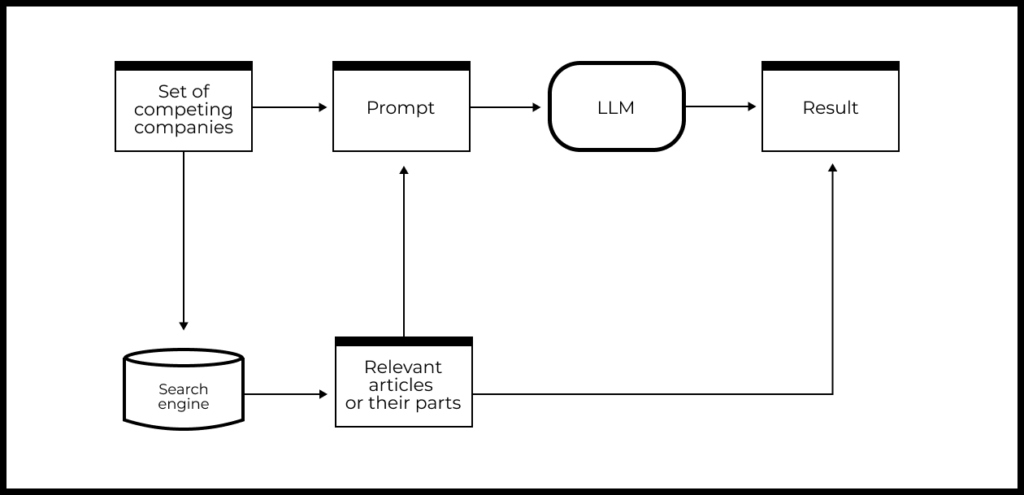
Imagine you need to regularly monitor news about your product’s competitors. Instead of manually searching and analyzing the news, you can use a combination of LLM and RAG, which will allow you to automate this process.
Suppose you have a list of competitor companies and you need to analyze their news every day. The pipeline implementation scheme might look like this:
- Search for news using a search engine (API).
- Download relevant documents and parse the text of the articles.
- Use an LLM to create a summary of the articles about each competitor.
- Add links to the source websites to the model’s response and return the results to the user.
RAG: Summary
Retrieval-Augmented Generation (RAG) is one of the most powerful advanced approaches to enhance the quality of LLM-based products. The idea is that we enrich the prompt with additional knowledge that was absent in the model’s training dataset.
RAG can be helpful if you need to:
- Use information that was not present in the LLM training dataset.
- Increase reliability of responses and reduce hallucinations in the LLM.
- Provide links to the sources of information on which the response was based.
Advantages of RAG:
- It is relatively simple to implement: for some problems, it can be realized with just five lines of code.
- It is faster and less costly than fine-tuning (additional training of a large language model).
- It allows for the rapid replacement of sources for prompt enrichment.
Disadvantages of RAG:
- To use RAG in production, you need to maintain specialized infrastructure, which can be quite complex (the complexity depends on the specific problem and data sources for RAG).
- Evaluating the quality of RAG is labor-intensive. The final result depends on multiple components, each of which needs to be evaluated separately (creating multiple test datasets, metrics, and annotations). For example, if it is necessary to add quotes from the data source, the quality of the quoting needs to be measured separately.
Learn more
All posts from the series
- How to choose your first AI/ML project: a guide
- How to discover potential AI applications in your business
- How we turned around an ML product by looking differently at the data
- Large language models: foundations for building AI-powered products
- Improve Retention by using ML/AI: what to do and what not to do
- Basic guide to improving product quality with LLM
- Advanced methods for improving product quality with LLM: RAG
- Why an ideal ML model is not enough to build a business around ML
- What to build and not to build in AI
- How to use AI for product and market research
***
To enhance your skills in working on AI products, you can benefit from:
Illustration by Anna Golde for GoPractice