
Products based on generative artificial intelligence have rapidly become a reality over the past years.
Just a few years ago, it was hard to imagine that models could generate images based on text or write essays or poems on a given topic, and do so at a level comparable to humans. Today, millions of people use products based on generative models to solve various problems.
ChatGPT is one of the most striking examples of products built on generative AI. Even without traditional marketing, it managed to become the fastest-growing service in history.
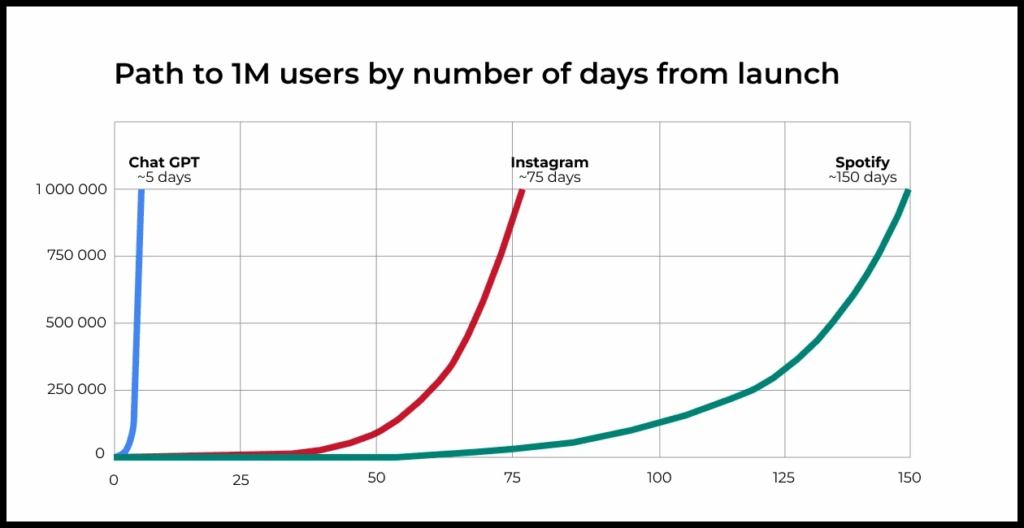
Many are looking to these technologies for ways to become more productive and solve new problems. Businesses are no different: CEOs and company founders are actively demanding their teams find ways to integrate generative AI solutions into their products.
But to truly create value with these technologies, it is essential to understand their fundamentals: how they work, where they can be beneficial, and what limitations and risks they entail.
In this article, we will explain in simple terms and without complex mathematics how large language models (LLMs), a subset of generative AI technology for working with text, work. This will help you to understand the capabilities of LLMs and build products based on them.
How large language models work
The term large language model (LLM) does not have a strict definition, but it generally refers to models that contain a massive number of parameters (billions) and have been trained on vast amounts of textual data.
The working principle of such models is quite simple:
- The model receives an “input prompt” (a user query or a set of words) and then selects the most appropriate word that should follow.
- After this, the generated word is appended to the prompt and fed back into the model, and it selects the next word.
- The cycle repeats until the model emits a special ending word or hits a predefined number of words.
This results in a “plausible continuation” of the initial query. To the user, it appears as a response that makes sense.
In this context, the prompt (hint, seed) is the main control element. Text generation occurs precisely based on the initial query, so by modifying and optimizing the prompt, you can control and improve the model’s output.
How LLM generates coherent text
Let’s examine how exactly LLMs generate plausible continuations of the input prompt.
Suppose the model is given the prompt “AI today transforms.” How does it construct a reasonable sentence further?
Imagine that we scanned the entire internet and found all instances where the phrase ‘AI today transforms’ is mentioned.
After that, we took all the words following this phrase and calculated the probability of each of them occurring. For example, we might obtain the following result:
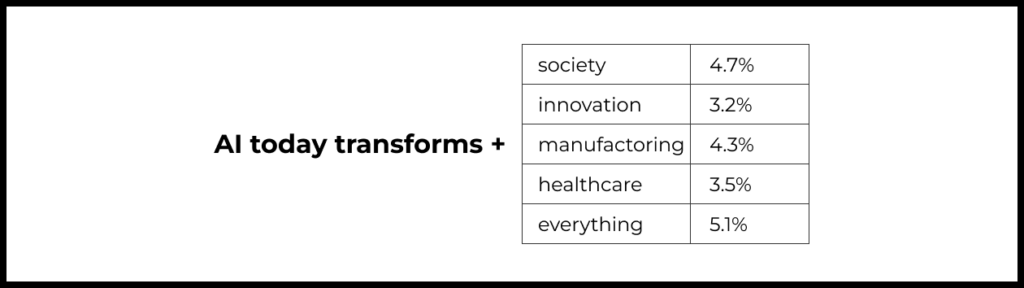
After this, based on these probabilities, the next word can be chosen. In this case, the model might add the word “everything” to ”AI today transforms.” However, it might also choose another word, depending on the model’s settings and the problem it is solving. For example, for creative problems, it is suitable to not always choose the word with the highest probability. This makes the language more “alive” and original.
We now have the original string with the newly added word: “AI today transforms everything.” In the next step, this updated string is given to the model and the process repeats itself. The LLM must determine what the next word should be based on the text provided to it as input. After adding a new word, the process of searching for the next word repeats — and so on.
In the example above, we demonstrated schematically how an LLM works by selecting the next words in a sentence. However, in reality, an LLM operates not with words, but with the “meaning” of words and sentences. Let’s discuss what this means.
How LLM understands the meaning of text
The explanation provided above is just the tip of the iceberg. As of today, it is not possible to confidently and simply explain how exactly an LLM “understands” text, but we can highlight several important components of this process:
LLMs represent each word as a point in a multidimensional space. This space is usually very complex. For example, in GPT-3 models, the dimensionality is about 10,000, meaning that a set of around 10,000 numbers are used to describe each word, often referred to as an “embedding.”
↓
When trained on massive amounts of data, LLMs can calculate embeddings in ways that semantically similar words have values that are closer to each other, and mathematical operations on them (e.g., similarity comparison, addition, averaging, etc.) start to have practical meaning. This allows the model to find synonyms, compare the meaning of texts, and paraphrase texts. Thus, the model works not with actual words, but with their meanings.
↓
LLMs model the relationships between words. When determining the next word, its probability will depend on the meaning of all previous words and their position in the sequence. This mechanism is called “causal self-attention,” and it allows the model to understand the meaning of words based on the context of their usage.
↓
Large text datasets are used to train the model. Modern models can be trained on tens of terabytes of text. This enables the model to ingest a vast amount of information and, in a sense, acquire universal knowledge about almost everything. Some studies show that LLMs develop a “world model” that helps them reason about natural and logical things. However, it is important to consider that this knowledge directly depends on what the model was trained on (which can easily include inaccurate and unreliable data).
↓
The model itself has an extremely large number of parameters: tens, and sometimes hundreds of billions of parameters. This allows it to “remember” the rules and structures of many languages, including programming languages, meanings of words and terms, writing styles, and rules of logical reasoning.
↓
Pre-trained models are often further trained for a specific problem. The problem could be a dialogue, question-answering, text completion or editing, or classification. Fine-tuning occurs using data that reflects the specifics of the final problem. For example, for fine-tuning ChatGPT, a team of experts meticulously compiled large sets of question-answer pairs in dialogue form. Another method is to fine-tune the model based on manual feedback on which responses are good or bad. This fine-tuning stage ensures the model follows the instructions specified in the prompt.
Risks and features of applying LLM
If you’re considering using LLMs in your product or developing a new service, it’s important to keep the following in mind.
First, LLM can generate anything. The responses of modern models do not undergo fact-checking. This means you might receive inaccurate, dangerous, or toxic information in the response. This issue has been termed “AI hallucinations” and is currently a focus for leading researchers.
- Using unchecked information can result in reputation loss.
- Inaccurate information created with the help of LLM is already becoming the subject of several lawsuits.
- People tend to trust LLM responses, which can create new cybersecurity and scam threats.
Second, the length of the text that can be input into the model is limited, and the model’s response length also has limitations.
- This means that if you want to process a large text—for example, translate a book, summarize a long article, or process a very lengthy instruction, you will need an algorithm for processing the text in parts.
Third, it’s important to be aware of the risks associated with sending personal and corporate data when using models through cloud service APIs.
- There have already been high-profile cases of corporate data leaks in ChatGPT — such as the case with Samsung employees
- Some large companies are setting rules that prohibit employees from using ChatGPT — such as Apple
- Data leaks can occur within the cloud services themselves — such as OpenAI
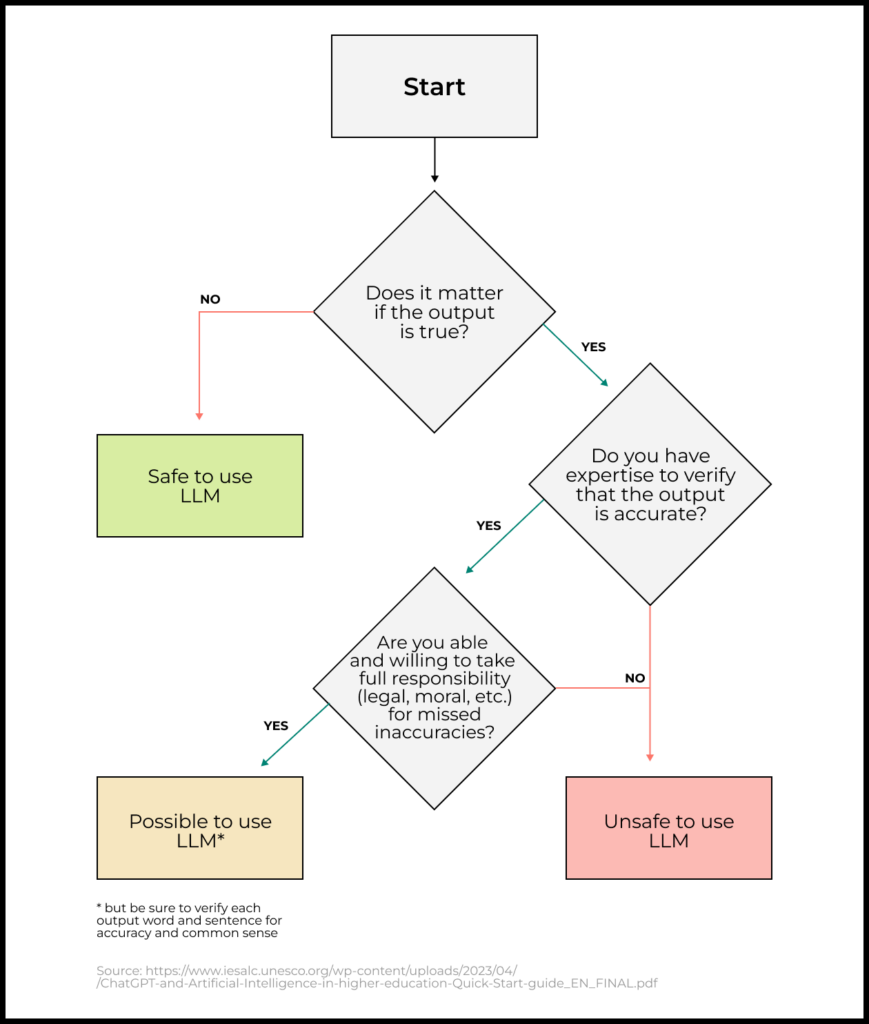
How to assess the prospects of using LLM in your product
To decide on whether to use LLMs in your product, ask yourself: “If the model generates implausible/false/toxic information, will it be safe for the user?”
- If yes, LLM can be used.
- If not, it is better either to refrain from using LLMs in your product or to implement filtering rules that block such content and minimize the risks.
For the use of LLM in products and services, the safest cases are when the model’s response undergoes additional processing through verification scenarios or is used as an assistant/helper for a person who is aware of the limitations of this technology and can prevent and correct the negative outcomes.
Examples of major products based on LLM
Here are some examples of new successful products built on LLM models. We will explore a more comprehensive list of successful LLM application cases for end-users in the following materials of the series.
- ChatGPT – a general chatbot
- Anthropic — provides an API for embedding LLM into products, for example, the ‘Ask AI’ feature in Notion is built on this API
- Copilot — helps developers write code faster
- Jasper — a service for creating website content, articles, and social media posts
- Perplexity AI – a conversational search system
Learn more
We’ve already addressed many questions regarding the application of AI in products. Check out our other articles.
— What to build and not to build in AI
— Basic guide to improving product quality with LLM
To enhance your skills in working on AI products, you can benefit from our courses:
Illustration by Anna Golde for GoPractice