
Failing fast and often will help you learn from your mistakes sooner rather than later. This is an advice you hear often from successful product managers. But what you hear less often is that not every failure is a successful learning experience.
A product’s success is largely dependent on coming up with a hypothesis and designing the right tests. Without those elements, you might draw the wrong conclusions and steer your project in the wrong direction.
In his guest post for the GoPractice blog, Ethan Garr, VP of product at TelTech.co, shares some hard-earned experience in product testing. Through concrete case studies, Ethan shows us how to avoid key pitfalls when designing tests for hypotheses.
→ Test your product management and data skills with this free Growth Skills Assessment Test.
→ Learn data-driven product management in Simulator by GoPractice.
→ Learn growth and realize the maximum potential of your product in Product Growth Simulator.
→ Learn to apply generative AI to create products and automate processes in Generative AI for Product Managers – Mini Simulator.
→ Learn AI/ML through practice by completing four projects around the most common AI problems in AI/ML Simulator for Product Managers.
Many of the lessons of growth are often learned the hard way.
That is why the growth hacker’s “Fail fast” maxim is one of our favorites. We love it because success gives your team confidence while failure generates competence.
Just as long as you’re failing at the right things!
Every time an experiment fails because your hypothesis was incorrect, it’s a win. Your team can learn something and use that to inform your next decision. But if your tests are failing to yield results because they are flawed to begin with, you’re not really getting anywhere.
In “How to Kickstart Your Growth Process,” I wrote about our growth team’s struggles at TelTech to implement the growth methodology. Today, I want to share four case studies from tests we screwed up royally! Hopefully, by understanding how and where we went wrong, you will be able to learn from our mistakes and avoid some costly errors of your own.
It’s OK to make mistakes, just don’t make the same ones twice.
Getting tests off the ground is difficult. There are many stakeholders with different perspectives involved, multiple technologies being employed, and many unknowns to be reconciled. Our failures will help you avoid some pitfalls, but know that you are going to botch a few regardless.
The key to successful testing is to learn the questions you need to ask yourself before you invest resources. This way your organizational process isn’t pre-destined to repeat errors that could have been avoided.
So with each case study I will provide some thoughts as to what we should have done in hindsight so that you can apply that learning to your own experimentation process.
Case Study 1: A Failure of Hypothesis
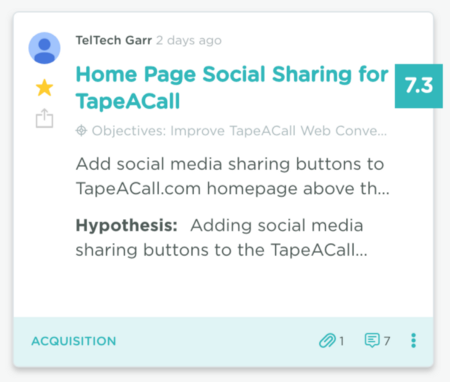
Test name: Home Page Social Sharing for TapeACall
TapeACall is an app that allows you to record inbound and outbound iPhone calls.
Hypothesis: Adding social media buttons to the TapeACall homepage will add credibility, thereby increasing signups.
How the mess began
Looking at that hypothesis now it is hard not to be embarrassed, but one of the dangers of high tempo testing is that to maintain a high testing cadence you will run tests that are neither well-conceived or ready to be run.
This hypothesis was exploratory in nature: “by changing X into Y, something will happen.” However, a good hypothesis looks like this: “By changing X into X, I can get more prospects to X, and thus increase X.” (credit CXL Live 2015, Michael Aagaard of Unbounce)
Our hypothesis was flawed in that it didn’t really identify success; “increasing sign-ups” as a KPI means that any improvement is a success, and that’s just not true; there are other factors.
Worse than that, somewhere in this pseudo-hypothesis was the idea that social sharing buttons add credibility to the site. So, even if they are distracting users from our download and purchase CTAs, this hypothesis assumed there might be underlying value that wasn’t really measurable.
How we made it even worse
We added these out-of-place sharing buttons to our home screen, which drove very few shares and a whopping two attributable sign-ups in two months.
That should have been enough to know this was not going to work, but we justified keeping the buttons longer because of the assumption that we would get some positive effect when visitors bypassed our own on-screen CTAs to purchase directly from the App Store.
I am not against social sharing buttons, but practically, they make a lot more sense after a visitor becomes a user and gets value from the product, not before they have had an aha moment.
With no measurable success, the product owner wanted them gone, the growth hacker who created the test wanted them to stay, and the situation got heated. In the absence of data, I sided with the product owner and we finally took them down.
What you can learn from this
A weak hypothesis can cripple an experiment before it starts. It all but ensures that you will create an even weaker set of success metrics, and if you don’t have a clear picture of what success looks like and how it will impact broader growth goals then any result can be interpreted the wrong way.
When you plan tests in your growth meetings your team should be asking the tough questions of each other’s experiment ideas. The tough questions are not, “is this a good idea?” The tough questions are:
- What does success look like? How will this impact broader growth goals?
- Do we have the tools to measure success?
- What is the plan if we get or do not get the expected results?Creating a clean, sound hypothesis, and ensuring you are discussing success metrics early, can help you avoid these kinds of mistakes.
Case Study 2: A Failure of Team Communication
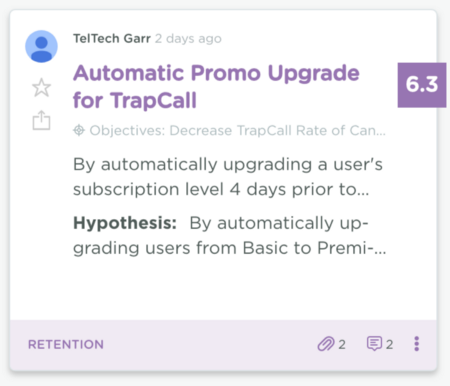
Test name: Automatic Promo Upgrade for TrapCall
TrapCall unmasks blocked caller ID and protects against harassment from unwanted callers.
Hypothesis: By automatically upgrading users from Basic to Premium for one week, we will increase retention 5–10%, and drive 3–5% more paid upgrades.
What we were trying to do
One of the interesting dilemmas of SaaS is that often your best retention features are relegated to your higher plans, even though most consumers will select your lowest plan to see if the product is valuable to them. While freemium models deal with this by exposing you to the full feature set from the outset, they aren’t always practical.
For us, this meant that many of our basic plan subscribers would cancel their subscriptions just prior to their first renewal. We were relatively optimistic that if we could delight our users with our more compelling retention features at exactly the right time we could change this dynamic.
It was critical to the experiment that the free upgrade we would give to our users would start before, and end after, the user’s monthly renewal date. To accomplish this, we would have to hack our billing process to bill a user at their chosen subscription level, not at their artificial promo subscription level.
Where it all went horribly wrong
The engineer on the project didn’t understand the nuances of the test, and when he ran into the billing system’s complexity, he made the decision to move the start date of the promotion to 10 days before the user’s renewal. He never communicated this decision to the test owner who would have explained that this would break the experiment.
The test results were terrible. We did see a small bump in upgrades, but we accelerated cancellations significantly. Only weeks later, while we were looking at some data did we discover what had actually happened.
What you can learn from this
The growth mentality is built on speed and agility, but the effectiveness of the process is dependent upon good team communication.
At the time, our development team was a shared resource across our portfolio, so the engineer wasn’t embedded on TrapCall’s growth team. He did not have direct ownership of the experiment’s success.
Teaching everyone in your organization their role in growth is the best way to facilitate good communications through the experimentation process. An engineer’s job isn’t to just write code, it is to write code that ensures an experiment’s hypothesis can be measured.
Furthermore, you can see that even a minor miscommunication can completely derail a test. You need to be able to trust people to make good decisions as to how best to accomplish goals, but you need to facilitate discussions from the growth meeting forward to ensure that these decisions are not made in a vacuum.
Case Study 3: A Failure of Process
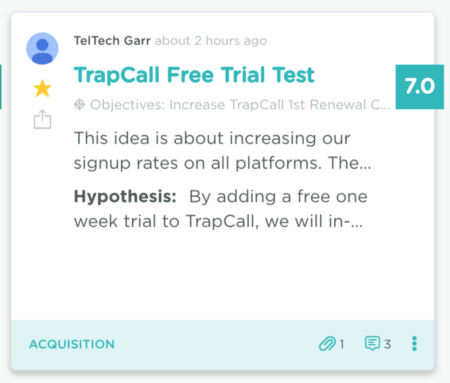
Test name: TrapCall Free Trial Test
Hypothesis: By adding a free one week trial to TrapCall, we will increase signups 4X, converting 50% of trials to paid subscriptions, thereby doubling new user signups, while maintaining our average LTV.
Why we thought this would be a winner
We were enthusiastic about this test because it was already working for RoboKiller, our app which stops telemarketing calls on iPhone. So with a very simple MVP, and a minimal drain on resources we quickly launched what we thought would be a surefire winner.
Almost immediately we saw some encouraging results in terms of signups and average order value, but with a one-week trial, we knew that we wouldn’t be able to measure paid user conversions for a full week.
Our uh-oh moment
After a week, we saw that our conversions were zero, but not because people didn’t want TrapCall.
It turned out we never gave ourselves the chance to convert trial users because we were not saving credit card information we would need to bill users at the end of the trial. We blew it, and it cost us quite a bit of revenue.
Our culture is not about blame, which is one of the things I truly love about TelTech, but we are very focused on learning from our mistakes. So we started to look at the breakdown. Obviously, the backend code should have supported the purchase, but our developers also rely on QA to ensure everything works properly.
QA thought they could only test the initial signup interactions because of the one week delay between signup and conversion. The delayed payment was never tested.
Ultimately, we realized our process was flawed, and we learned that we had to make adjustments. Now, from our vision documents forward, we know exactly what the “Definition of Done” is for each stakeholder and we make sure that we can test each element before we start.
What you can learn from this
Not every test is going to be simple. Even an MVP may have many moving parts. With each layer of complexity you will likely add more stakeholders. As that happens, it is really important that your processes put a heavy focus on ensuring that good communications flow across the team and organization.
It is easy to get complacent and to just throw tests up to see what happens, but that is a dangerous approach when time and money are at stake.
Case Study 4: A Failure of Perspective
Test name: Add Apple Pay to SpoofCard
SpoofCard protects your privacy and identity by allowing you to change your caller ID.
Hypothesis: By adding the credibility and security of Apple Pay as an additional SpoofCard payment option, we will reduce pricing page abandonment 10–15%, thereby increasing new user sales 10–15%.
It seemed so straightforward
This was a well-organized experiment with a clearly written vision document. The problem was that we failed to step back and look at the bigger picture.
Everything about this test made sense. We had success with a similar test where we had added PayPal to the product a few months earlier, and a similar company had touted their success with implementing Apple Pay at a conference I had attended.
Our product owner did everything right from inception through development and managed her design and development resources efficiently to deliver the feature for testing in about two weeks.
. . . But what a waste
Unfortunately, instead of 10% growth, we saw 10 users…total! I had no problem with the flop, that happens. What I did have an issue with was the fact that we could have learned the same thing with 15 minutes of design work, and that only came into focus because the failure was so spectacular.
A “Pay with Apple Pay” graphic and a “Pay Now” button that led to a “Coming Soon” page would have yielded the same, horrific results with minimal work. So to measure something that required less than an hour of work, we had wasted weeks of precious development time.
What you can learn from this
You have limited resources, and you have to be smart about how you use them. In your growth meetings, it is your job, as your team’s growth leader to make sure your team is always asking the question, “is there a simpler way to accomplish this goal?”
Remember, you are only going to be right a small percentage of the time, so fail fast to get to learnings sooner.
As ideas come into focus the process breeds excitement and enthusiasm, which is great. That is what makes the growth process fun and keeps teams engaged. But being able to look at the larger picture needs to be part of the process too. As the leader of growth, you should make that your responsibility.
So here is the takeaway
High-Impact Testing is the real goal of High-Tempo Testing. You can run a lot of crappy tests and call it high tempo testing or you can run a lot of good tests and get the growth impact that is your ultimate goal.
Being wrong about your hypothesis is not a mistake, it is the likely result of most tests. Being flawed in your approach to experimentation, however, is definitely a mistake… and often costly.
From flawed hypotheses and bad engineering to over-complication and bad communication, I have shown you some of the ways we ruined some of our experiments at TelTech. You can learn from each of these errors to increase the likelihood that your own tests will be successful.
With a little luck you will make different mistakes, but ultimately if your process is effective, like me you will look at even these failures as part of growth. I am not necessarily glad we made these blunders, but I am proud of our team for never being afraid to make new ones.
→ Test your product management and data skills with this free Growth Skills Assessment Test.
→ Learn data-driven product management in Simulator by GoPractice.
→ Learn growth and realize the maximum potential of your product in Product Growth Simulator.
→ Learn to apply generative AI to create products and automate processes in Generative AI for Product Managers – Mini Simulator.
→ Learn AI/ML through practice by completing four projects around the most common AI problems in AI/ML Simulator for Product Managers.